Muhammad Uzair Khattak
PhD Candidate, EPFL, Switzerland - MSc from MBZUAI, Abu-Dhabi - BSc from SEECS, NUST, Pakistan.

Lausanne, Switzerland
Hi, I am Muhammad Uzair, a PhD candidate at VILAB at EPFL supervised by Prof. Amir Zamir and PD. Dr. Federico Tombari. Previously, I completed my MSc in Computer Vision at the IVAL lab at Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI), where I was supervised by Dr. Salman Khan and Dr. Fahad Khan. At MBZUAI, I was also co-supervised and mentored by Dr. Muzammal Naseer.
My current research interests include developing foundational video models using multimodal abstract spaces, and studying the implications of multimodality for world modeling, long-horizon prediction, and video generation tasks.
My master’s research focus was on adapting foundational multi-modal models for vision tasks including image recognition, object detection, and video action recognition. The goal was to steer these foundational models for downstream tasks with limited data (few-/zero-shot) while maintaining their pre-trained generalization for novel tasks. I also worked on pretraining vision-language models for the medical imaging domain, and on complex video reasoning using Large Multimodal Models (LMMs).
Email / Google Scholar / Github / Twitter / CV
News
| Dec 18, 2024 | We have released UniMed, an open-source and large-scale multi-modal medical dataset comprising 6 diverse medical modalities. Building upon UniMed, we train UniMed-CLIP, a family of strong medical VLMs. Dataset, models and demos are available here. |
|---|---|
| Dec 10, 2024 | Our work on text-only prompt learning for foundational Vision-Language models got accepted into AAAI’25! Congratulations to all co-authors! |
| Sep 1, 2024 | I have started my PhD studies at EPFL, Switzerland. |
| May 9, 2024 | We have released CVRR-ES: Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs. More details on the project page. |
| Feb 22, 2024 | Invited talk on Multi-modal learning @ Amazon Prime Video. |
| Feb 5, 2024 | Invited talk on our recent ProText work at Cohere For AI. (Slides / Recording) |
| Jan 5, 2024 | We have released ProText, a novel framework to adapt Vision-Language models with text-only data. More details on the project page ! |
| Dec 16, 2023 | Invited talk on our recent PromptSRC work at Computer Vision Talks. |
Selected publications
* denotes joint first authors
2026
-
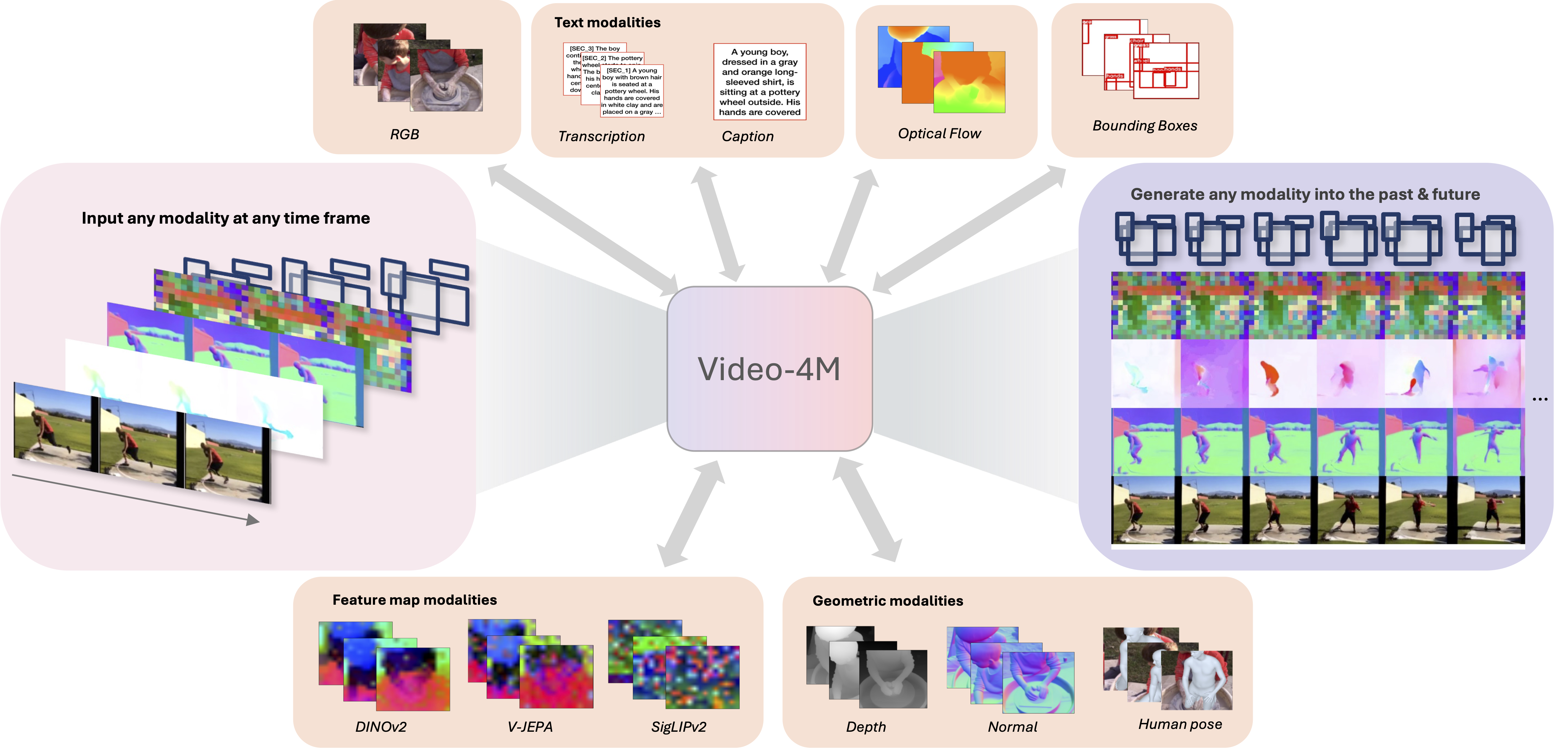 Any-to-Any Video Modeling in Multimodal Abstract SpacesUnder Review, 2026
Any-to-Any Video Modeling in Multimodal Abstract SpacesUnder Review, 2026

2024



2023





2022
-
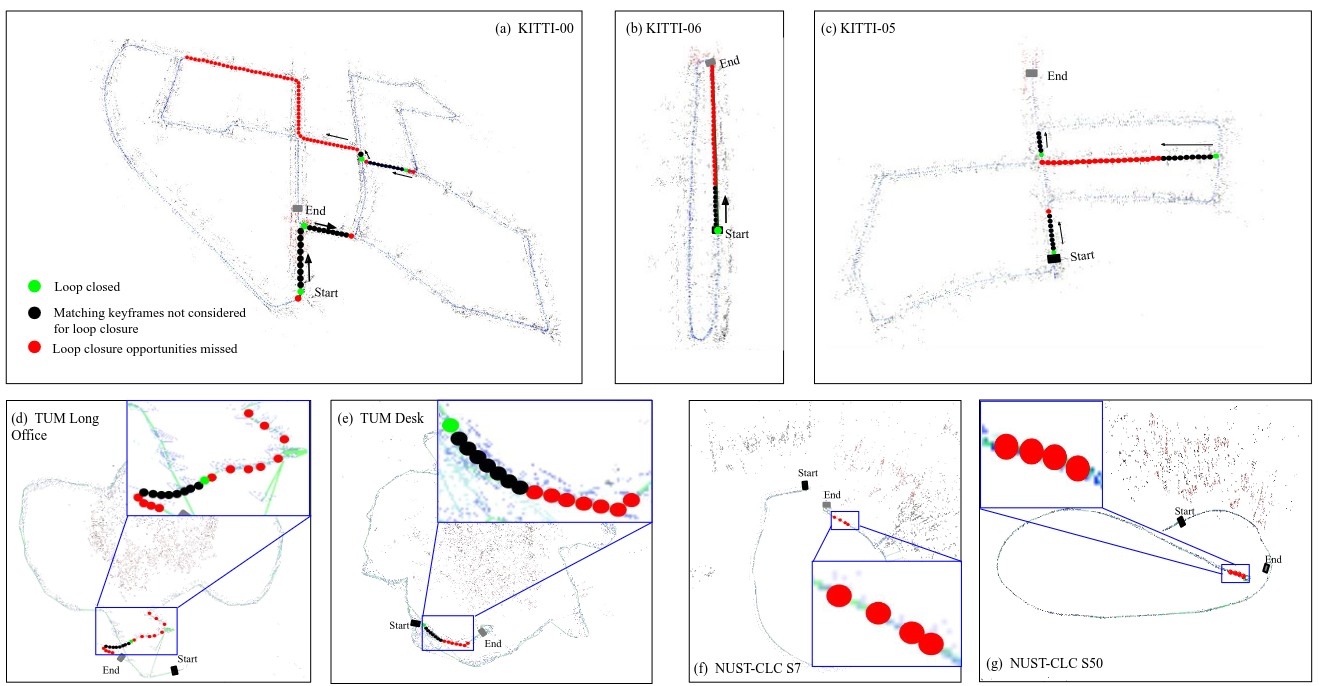 Investigating and Improving Common Loop Closure Failures in Visual SLAMAutonomous Robots, Oct 2022
Investigating and Improving Common Loop Closure Failures in Visual SLAMAutonomous Robots, Oct 2022

