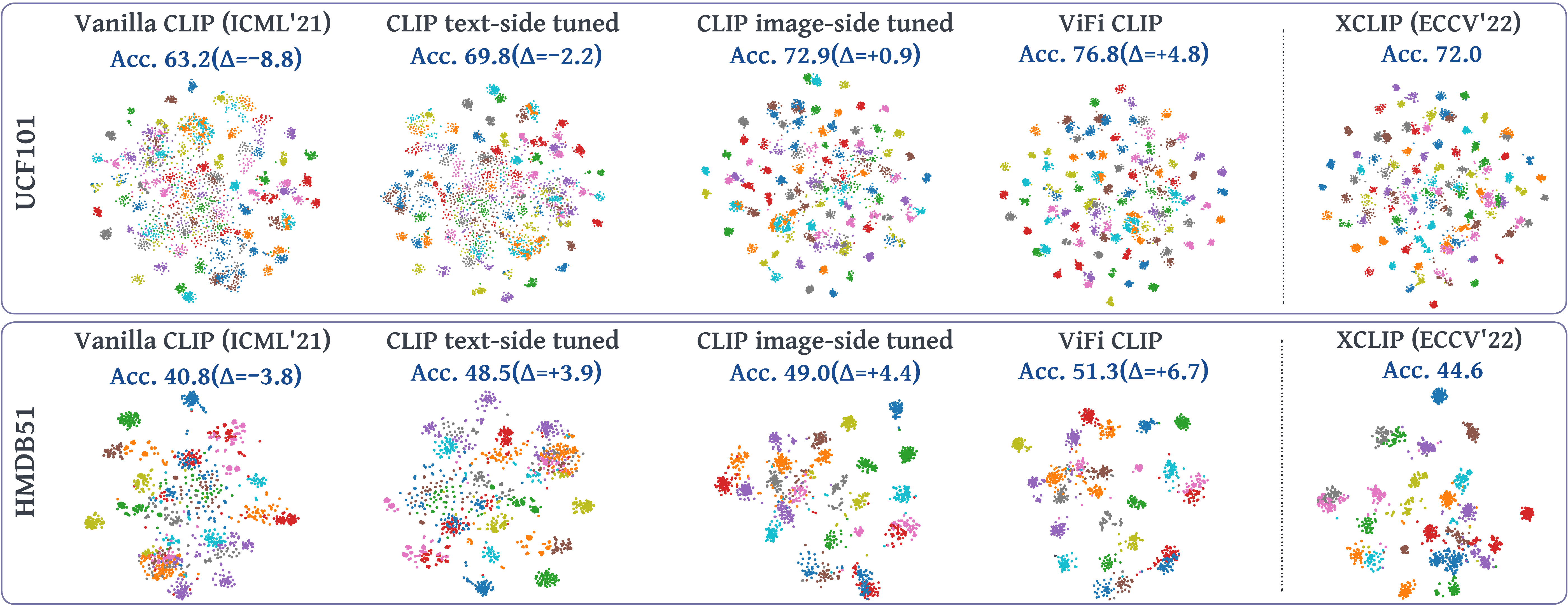
This work explores the capability of a simple baseline called ViFi-CLIP (Video Fine-tuned CLIP) for adapting image pretrained CLIP to video domain. The figure compares the zero-shot performance of vanilla CLIP and several of its variants adapted for videos (trained on Kinetics-400, evaluated on UCF-101 and HMDB-51). The t-SNE visualizations of video-embeddings obtained from ViFi-CLIP (4th col.) are compared with embeddings from vanilla CLIP (1st col.), individually tuned CLIP text (2nd col.) and image encoder (3rd col.) on videos, and recent state-of-the-art work, XCLIP [1] (last col.) (∆ represents difference over XCLIP). The embeddings of ViFi-CLIP are better separable, indicating that a simple fine-tuning of CLIP is sufficient to learn suitable video-specific inductive biases, and can perform competitive to more complex approaches having dedicated components designed to model temporal information in videos.
Abstract
Large-scale multi-modal training with image-text pairs imparts strong generalization to CLIP model. Since training on a similar scale for videos is infeasible, recent approaches focus on the effective transfer of image-based CLIP to the video domain. In this pursuit, new parametric modules are added to learn temporal information and inter-frame relationships which require meticulous design efforts. Furthermore, when the resulting models are learned on videos , they tend to overfit on the given task distribution and lack in generalization aspect. This begs the following question: How to effectively transfer image-level CLIP representations to videos? In this work, we show that a simple Video Fine-tuned CLIP (ViFi-CLIP) baseline is generally sufficient to bridge the domain gap from images to videos. Our qualitative analysis illustrates that the frame-level processing from CLIP image-encoder followed by feature pooling and similarity matching with corresponding text embeddings helps in implicitly modeling the temporal cues within ViFi-CLIP. Such fine-tuning helps the model to focus on scene dynamics, moving objects and inter-object relationships. For low-data regimes where full fine-tuning is not viable, we propose a bridge and prompt approach that first uses fine-tuning to bridge the domain gap and then learns prompts on language and vision side to adapt CLIP representations. We extensively evaluate this simple yet strong baseline on zero-shot, base-to-novel generalization, few-shot and fully supervised settings across five video benchmarks.
Main contributions
ViFi-CLIP: We formulate and show the significance of an often neglected but simple baseline for transferring image-based CLIP model to video domain. ViFi-CLIP (Video Fine-tuned CLIP) shows that a simple fine-tuning of CLIP is sufficient to learn suitable video-specific inductive biases, and can perform competitive to more complex approaches having dedicated components designed to model temporal information in videos.
Base-to-novel generalization benchmark: We introduce base-to-novel generalization benchmark for video-domain for evaluating the generalization ability of models for video action recognition. This base to novel generalization is the first open-vocabulary video recognition protocol.
Bridge and Prompt approach: We show the effectiveness of our proposed bridge and prompt approach to first bridge the modality gap through fine-tuning followed by prompt learning in both visual and language branches of the CLIP model for low-data regimes.
ViFi-CLIP design
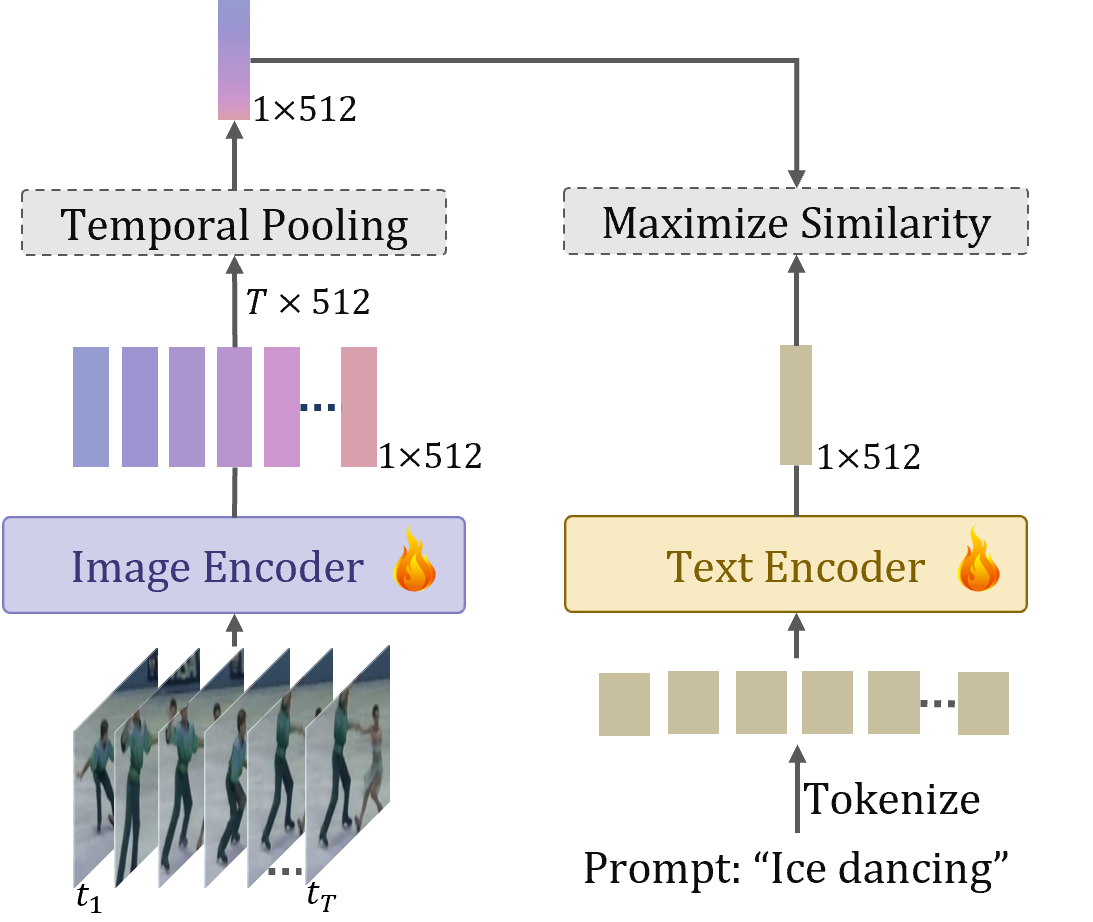
Overview of our simple baseline ViFi-CLIP for adapting CLIP to videos. We fine-tune CLIP on videos with minimal design changes that do not include modality specific components which we find to degrade the generalization ability of CLIP. Simple frame-level late feature aggregation via temporal pooling allows the exchange of temporal cues in the CLIP representation.
Base-to-Novel generalization setting
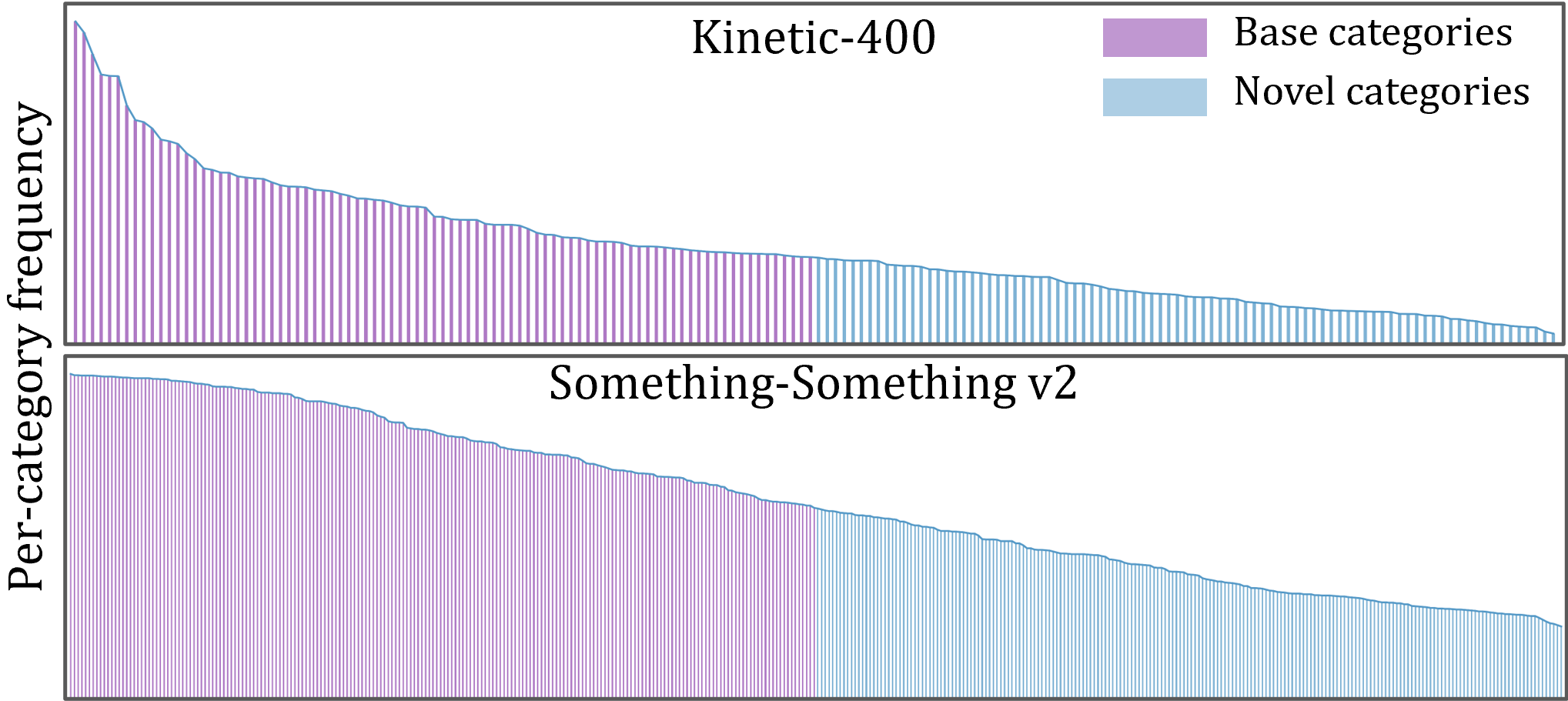
We introduce a base-to-novel generalization benchmark for video action recognition for evaluating model's generalization ability within a dataset. We split action recognition datasets into base and novel classes. The model is trained on base classes and evaluated both on base and novel classes. The proposed base and novel split categorizes the total categories into two equal halves, where the most frequently occurring classes are grouped as the base classes. Below figure shows the base-novel splits of Kinetics-400 (K-400) and Something-Something v2 (SSv2).
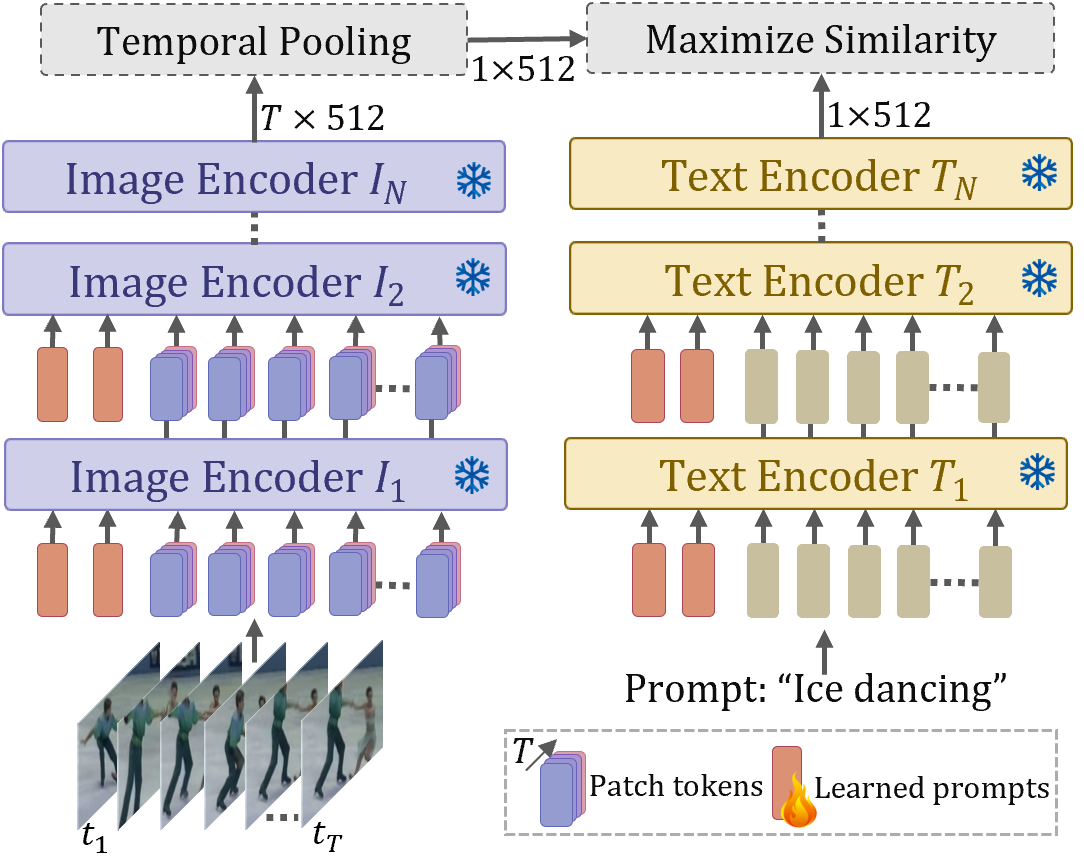
Bridge and Prompt in low-data regimes
We show the effectiveness of our proposed bridge and prompt approach to first bridge the modality gap through fine-tuning followed by prompt learning in both visual and language branches of the CLIP model for low-data regimes. Vision and Language prompts are used to fine-tune CLIP on downstream tasks. The proposed design is shown below.
Visualizations
Attention map visualizations
Attention map visualizations of ViFi-CLIP in comparison with vanilla CLIP on two examples from UCF-101 validation set. ViFi-CLIP learns inter-object relationships and scene-dynamics from temporal cues and focuses on fast-moving parts and objects, thereby demonstrating the ability to encode video specific information.

Generalization to out-of-distribution examples
Attention map visualizations from ViFi-CLIP shows impressive generalization. (Left): Visualization on a diffusion model generated (synthetic) video from Imagen [2] shows how ViFi-CLIP focuses on the body of the astronaut, the horse and its moving feet. (Right): Example of a rare scenario giraffe diving. ViFi-CLIP consistently attends to the giraffe at various locations: diving board, air, water-surface and under the pool.

Results
Base-to-novel generalization results
Here, we divide each dataset into base and novel classes. All models are trained on base classes and evaluated on both base and novel classes. Results are averaged over 3 seeds for each experiment. Top-1 accuracy is reported.
Kinetics-400
| ActionCLIP [3] | 32x224 | 61.0 | 46.2 | 52.6 |
| A5 [4] | 32x224 | 69.7 | 37.6 | 48.8 |
| XCLIP [1] | 32x224 | 74.1 | 56.4 | 64.0 |
| CLIP image-FT | 32x224 | 72.9 | 58.0 | 64.6 |
| CLIP text-FT | 32x224 | 73.4 | 59.7 | 65.8 |
| ViFi-CLIP | 32x224 | 76.4 | 61.1 | 67.9 |
HMDB-51
| ActionCLIP [3] | 32x224 | 69.1 | 37.3 | 48.5 |
| A5 [4] | 32x224 | 46.2 | 16.0 | 23.8 |
| XCLIP [1] | 32x224 | 69.4 | 45.5 | 55.0 |
| CLIP image-FT | 32x224 | 62.6 | 47.5 | 54.0 |
| CLIP text-FT | 32x224 | 70.0 | 51.2 | 59.1 |
| ViFi-CLIP | 32x224 | 73.8 | 53.3 | 61.9 |
UCF-101
| ActionCLIP [3] | 32x224 | 90.1 | 58.1 | 70.7 |
| A5 [4] | 32x224 | 90.5 | 40.4 | 55.8 |
| XCLIP [1] | 32x224 | 89.9 | 58.9 | 71.2 |
| CLIP image-FT | 32x224 | 86.4 | 65.3 | 74.4 |
| CLIP text-FT | 32x224 | 90.9 | 67.4 | 77.4 |
| ViFi-CLIP | 32x224 | 92.9 | 67.7 | 78.3 |
SSv2
| ActionCLIP [3] | 32x224 | 13.3 | 10.1 | 11.5 |
| A5 [4] | 32x224 | 8.3 | 5.3 | 6.4 |
| XCLIP [1] | 32x224 | 8.5 | 6.6 | 7.4 |
| CLIP image-FT | 32x224 | 9.2 | 8.5 | 8.8 |
| CLIP text-FT | 32x224 | 12.4 | 9.5 | 10.8 |
| ViFi-CLIP | 32x224 | 16.2 | 12.1 | 13.9 |
VL Prompting approach: Base-to-Novel
ViFi-CLIP is first trained on K400 and then vision and language prompts are further fine-tuned on the downstream datasets.
| HMDB-51 | 32x224 | 77.1 | 54.9 | 64.1 |
| UCF-101 | 32x224 | 95.9 | 74.1 | 83.6 |
| SSv2 | 32x224 | 15.8 | 11.5 | 13.3 |
Zero-shot results
All models are trained on Kinetics-400 and then evaluated directly on downstream datasets. Top-1 accuracy is reported.
| ActionCLIP [3] | 32x224 | 40.8 | 58.3 | 66.7 |
| A5 [4] | 32x224 | 44.3 | 69.3 | 55.8 |
| XCLIP [1] | 32x224 | 44.6 | 72.0 | 65.2 |
| CLIP image-FT | 32x224 | 49.0 | 72.9 | 62.2 |
| CLIP text-FT | 32x224 | 48.5 | 69.8 | 68.5 |
| ViFi-CLIP | 32x224 | 51.3 | 76.8 | 71.2 |
Few-shot results
Below table shows few-shot results of ViFi-CLIP for K=2, 4, 8 and 16.
| ViFi-CLIP | HMDB-51 | 2 | 32x224 | 57.2 |
| ViFi-CLIP | HMDB-51 | 4 | 32x224 | 62.7 |
| ViFi-CLIP | HMDB-51 | 8 | 32x224 | 64.5 |
| ViFi-CLIP | HMDB-51 | 16 | 32x224 | 66.8 |
| ViFi-CLIP | UCF-101 | 2 | 32x224 | 80.7 |
| ViFi-CLIP | UCF-101 | 4 | 32x224 | 85.1 |
| ViFi-CLIP | UCF-101 | 8 | 32x224 | 90.0 |
| ViFi-CLIP | UCF-101 | 16 | 32x224 | 92.7 |
| ViFi-CLIP | SSv2 | 2 | 32x224 | 6.2 |
| ViFi-CLIP | SSv2 | 4 | 32x224 | 7.4 |
| ViFi-CLIP | SSv2 | 8 | 32x224 | 8.5 |
| ViFi-CLIP | SSv2 | 16 | 32x224 | 12.4 |
NOTE: Few-shot results for other CLIP Fine-tuned variants and its comparison with previous SoTA are presented in our main paper (Table 3).
VL Prompting approach: Few-shot
ViFi-CLIP is first trained on K400 and then vision and language prompts are further fine-tuned on the downstream datasets in few-shot manner.
| HMDB-51 | 32x224 | 63.0 | 65.1 | 69.6 | 72.0 |
| UCF-101 | 32x224 | 91.0 | 93.7 | 95.0 | 96.4 |
| SSv2 | 32x224 | 6.7 | 7.9 | 10.2 | 13.5 |
Fully-supervised results on Kinetics-400
| ActionCLIP [3] | 563 | 32x224 | 83.8 | 96.2 |
| A6 [4] | - | 16x224 | 76.9 | 93.5 |
| XCLIP [1] | 287 | 16x224 | 84.7 | 96.8 |
| CLIP image-FT | 281 | 16x224 | 82.8 | 96.2 |
| CLIP text-FT | 281 | 16x224 | 73.1 | 91.2 |
| ViFi-CLIP | 281 | 16x224 | 83.9 | 96.3 |
References
BibTeX
If you use our approach (code, model or dataset splits) in your research, please consider citing:
@article{hanoona2022vificlip,
title={Finetuned CLIP models are efficient video learners},
author={Rasheed, Hanoona and khattak, Muhammad Uzair and Maaz, Muhammad and Khan, Salman and Khan, Fahad Shahbaz},
journal={arXiv:},
year={2022}
}