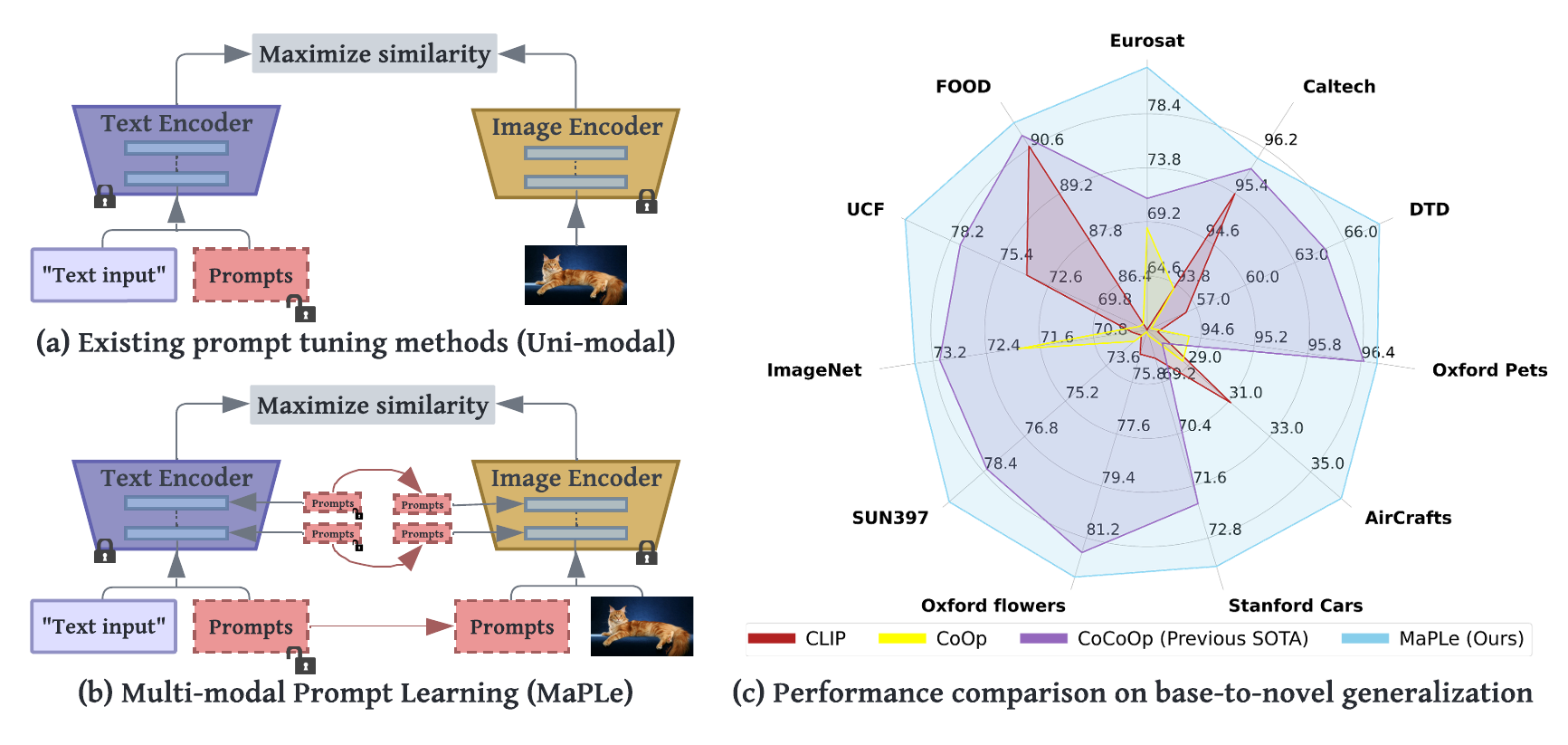
(a) Existing methods adopt uni-modal prompting techniques to fine-tune CLIP representations as prompts are learned only in a single branch of CLIP (language or vision). (b) We propose Multi-modal Prompt Learning (MaPLe) which introduces branch-aware hierarchical prompts that adapt both language and vision branches simultaneously for improved generalization. (c) MaPLe surpasses state-of-the-art methods on 11 diverse image recognition datasets for novel class generalization task.
Abstract
Pre-trained vision-language (V-L) models such as CLIP have shown excellent generalization ability to downstream tasks. However, they are sensitive to the choice of input text prompts and require careful selection of prompt templates to perform well. Inspired by the Natural Language Processing (NLP) literature, recent CLIP adaptation approaches learn prompts as the textual inputs to fine-tune CLIP for downstream tasks. We note that using prompting to adapt representations in a single branch of CLIP (language or vision) is sub-optimal since it does not allow the flexibility to dynamically adjust both representation spaces on a downstream task. In this work, we propose Multi-modal Prompt Learning (MaPLe) for both vision and language branches to improve alignment between the vision and language representations. Our design promotes strong coupling between the vision-language prompts to ensure mutual synergy and discourages learning independent uni-modal solutions. Further, we learn separate prompts across different early stages to progressively model the stage-wise feature relationships to allow rich context learning. We evaluate the effectiveness of our approach on three representative tasks of generalization to novel classes, new target datasets and unseen domain shifts. Compared with the state-of-the-art method Co-CoOp, MaPLe exhibits favorable performance and achieves an absolute gain of 3.45% on novel classes and 2.72% on overall harmonic-mean, averaged over 11 diverse image recognition datasets.
MaPLe design
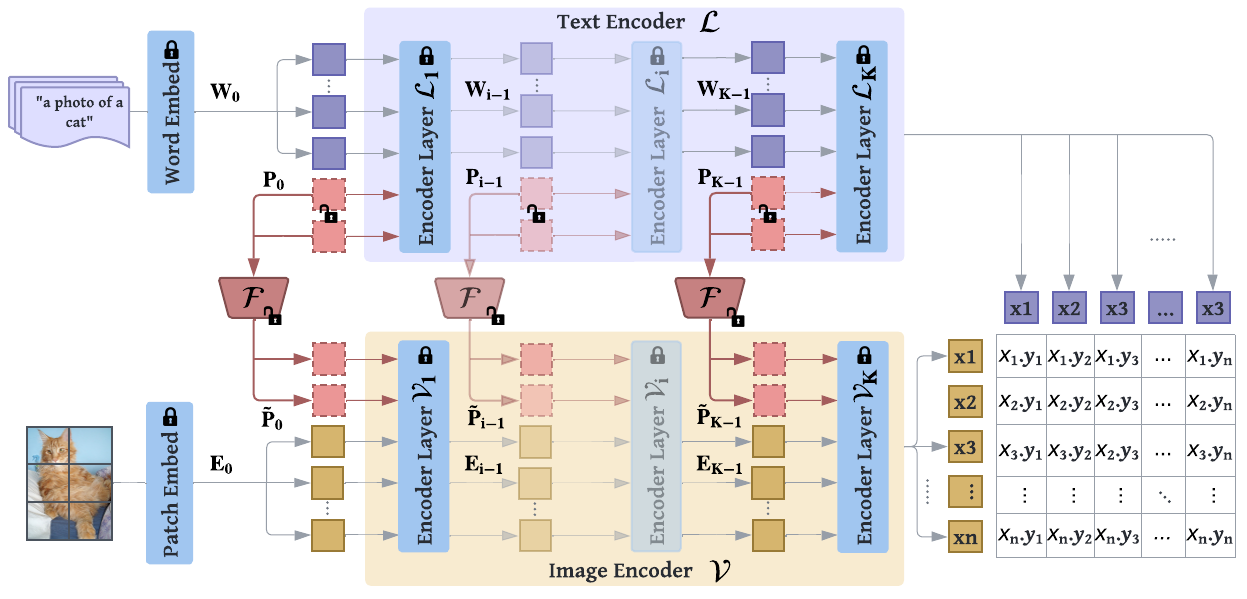
MaPLe tunes both vision and language branches where only the context prompts are learned, while the rest of the model is frozen. MaPLe conditions the vision prompts on language prompts via a V-L coupling function to induce mutual synergy between the two modalities. Our framework uses deep contextual prompting where separate context prompts are learned across multiple transformer blocks.
Prompting CLIP via Vision-Language prompts
Table below compares different possible prompting design choices as an ablation for our proposed branch-aware multi-modal prompting, MaPLe. Results reported below show accuracy for base and novel classes which are averaged across 11 recognition datasets over 3 seeds.
| Deep vision prompting | 80.24 | 73.43 | 76.68 | 5 |
| Deep language prompting | 81.72 | 73.81 | 77.56 | 5 |
| Independent V-L prompting | 82.15 | 74.07 | 77.90 | 5 |
| MaPLe (ours) | 82.28 | 75.14 | 78.55 | 5 |
MaPLe in comparison with existing methods
Below table shows comparison of MaPLe with state-of-the-art methods on base-to-novel generalization. MaPLe learns multi-modal prompts and demonstrates strong generalization performance over existing methods on 11 different recognition datasets.
| CLIP | 69.34 | 74.22 | 71.70 | - |
| CoOp | 82.69 | 63.22 | 71.66 | 200 |
| CoCoOp | 80.47 | 71.69 | 75.83 | 10 |
| MaPLe (ours) | 82.28 | 75.14 | 78.55 | 5 |
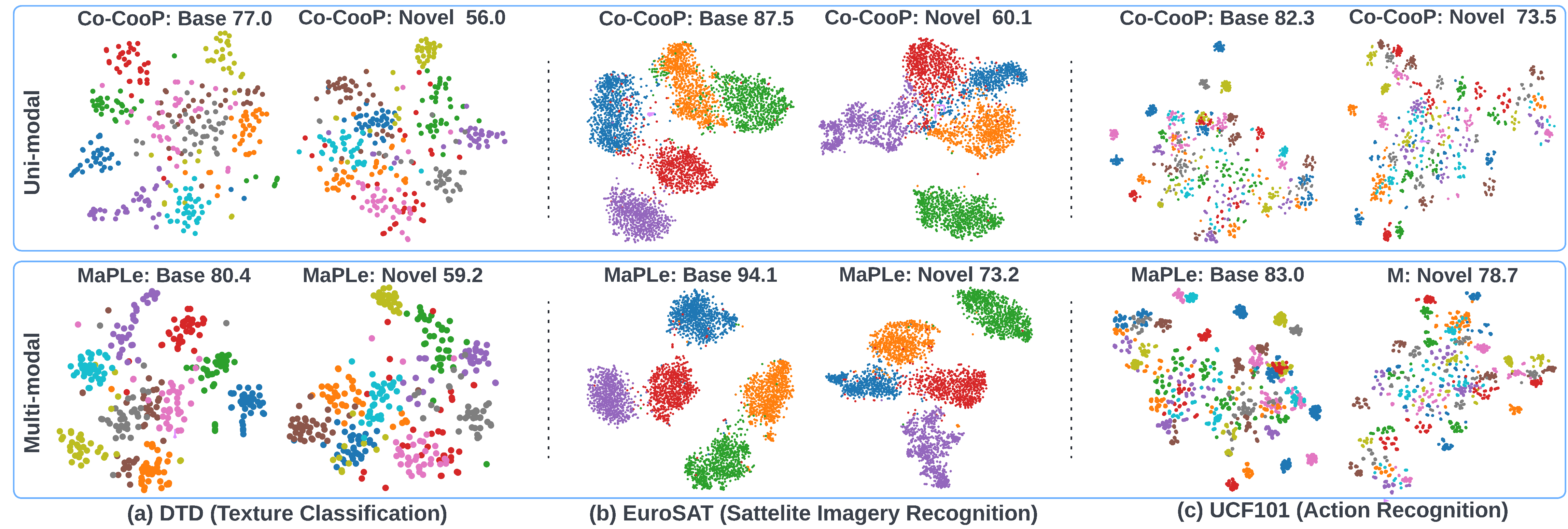
TSNE Visualizations
t-SNE plots of image embeddings in uni-modal prompting method Co-CoOp, and MaPLe on 3 diverse image recognition datasets. MaPLe shows better separability in both base and novel classes.
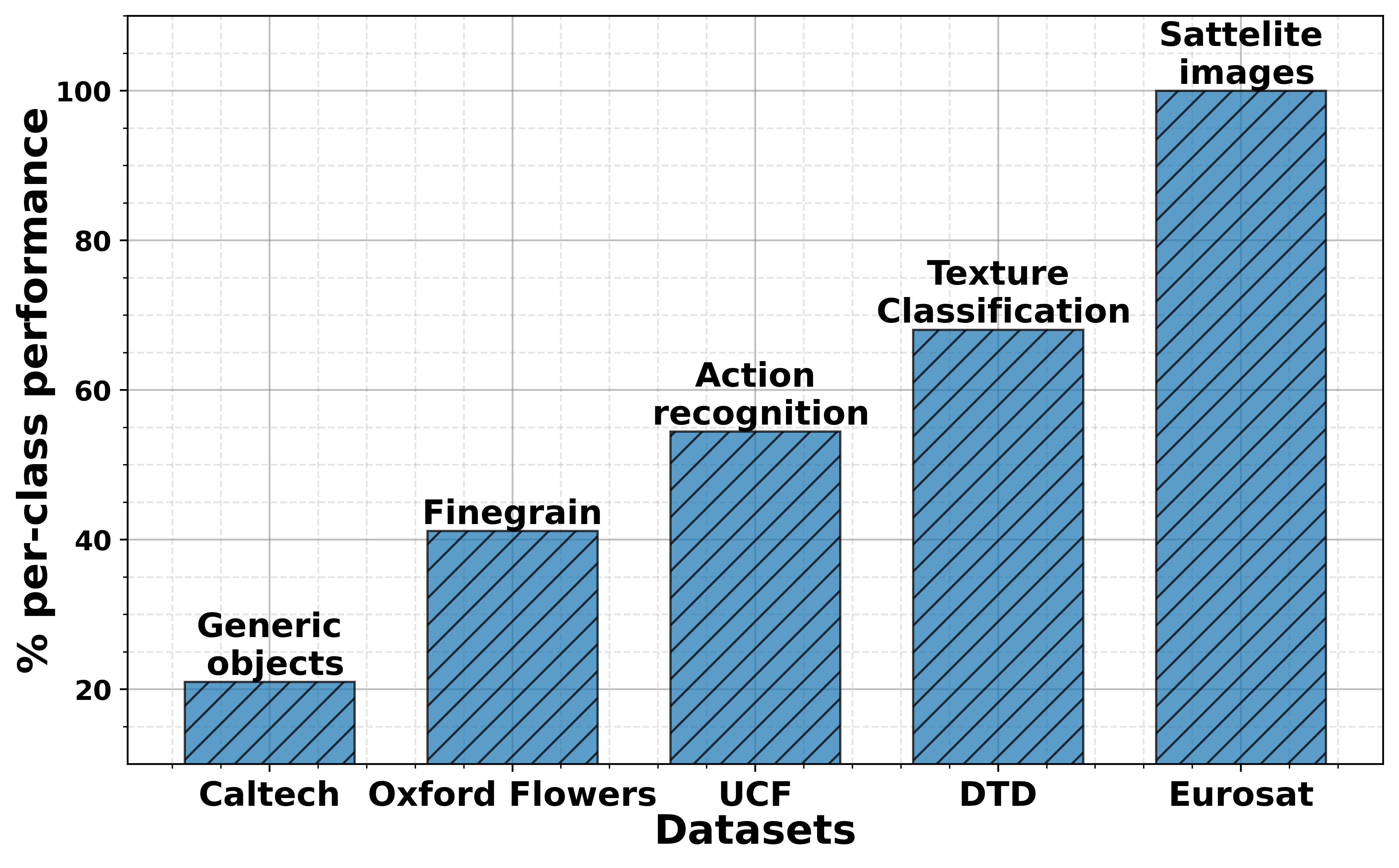
Effectiveness of MaPLe
Below figure shows percentage of classes where MaPLe > Co-CoOp for selected datasets in the order of increasing diversity (distribution gap w.r.t CLIP pretraining dataset, ie generic objects). The overall trend indicates that MaPLe is more effective than Co-CoOp as the diversity of the dataset increases.
BibTeX
If you like our work, please consider citing us.
@article{khattak2022MaPLe,
title={MaPLe: Multi-modal Prompt Learning},
author={khattak, Muhammad Uzair and Rasheed, Hanoona and Maaz, Muhammad and Khan, Salman and Khan, Fahad Shahbaz},
journal={https://arxiv.org/abs/2210.03117},
year={2022}
}