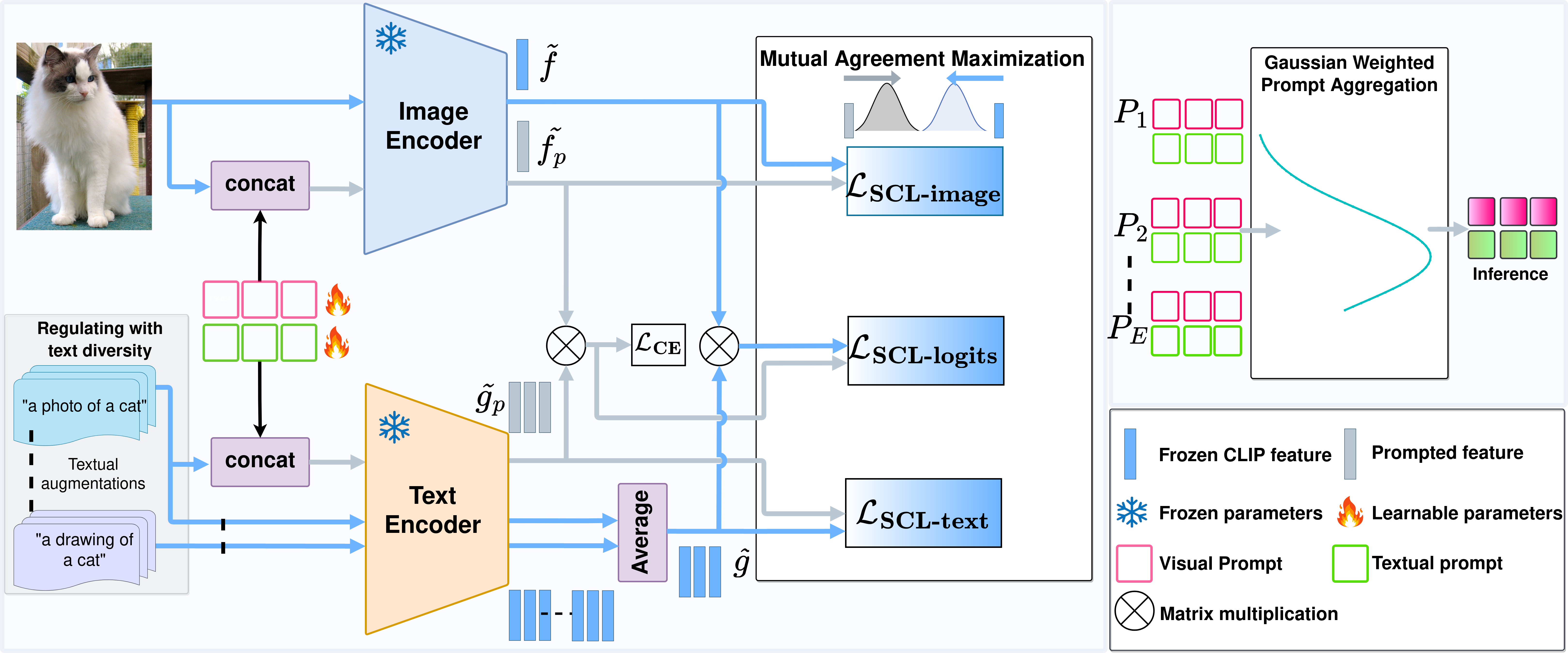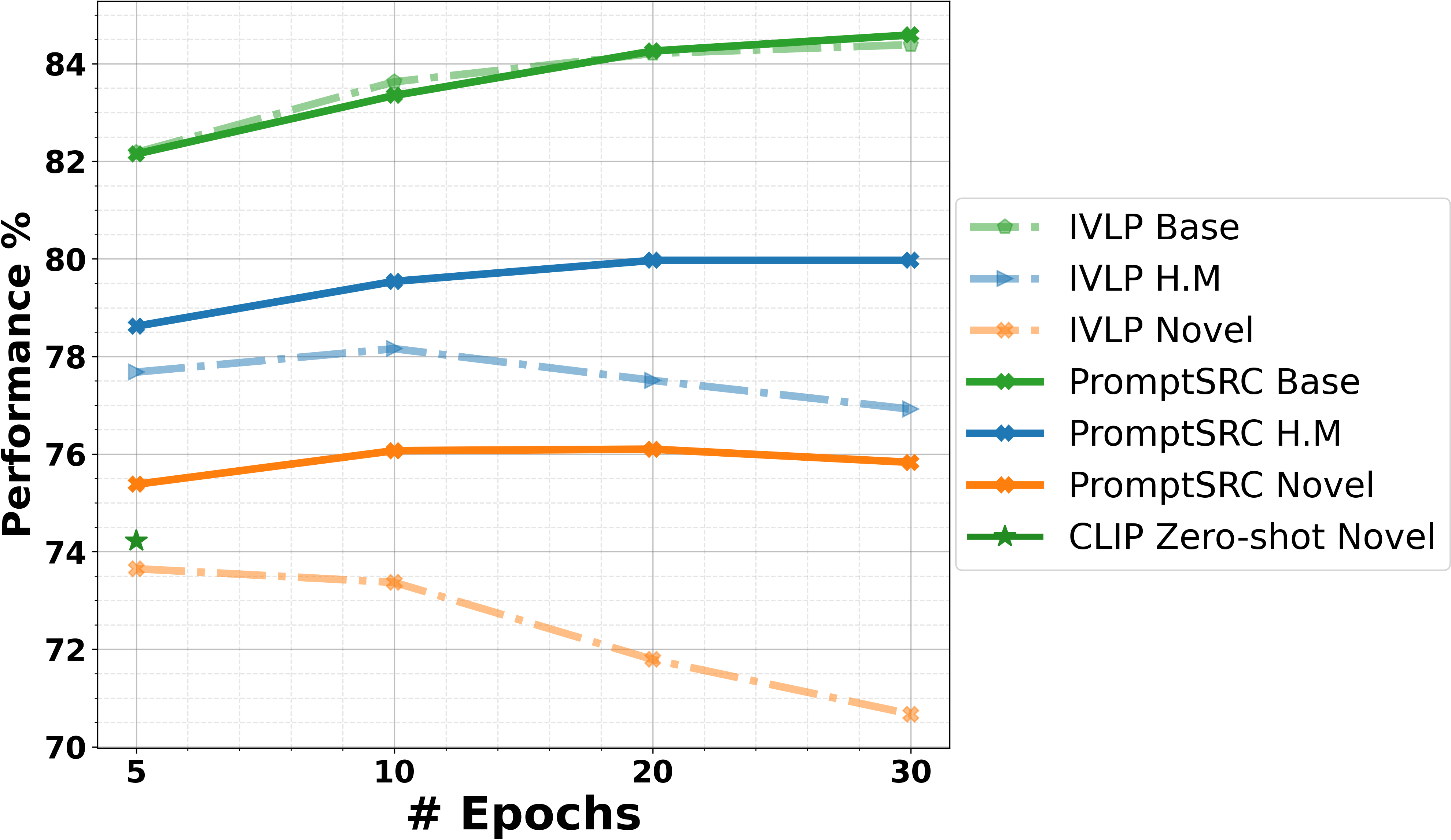
Left: Existing prompt learning approaches for foundational Vision-Language models like CLIP rely on task-specific objectives that restrict prompt learning to learn a feature space suitable only for downstream tasks and consequently lose the generalized knowledge of CLIP (shown in purple). Our self-regulating framework explicitly guides the training trajectory of prompts towards the closest point between two optimal solution manifolds (solid line) to learn task-specific representations while also retaining generalized CLIP knowledge (shown in green). Middle: Averaged across 11 image recognition datasets, PromptSRC surpasses existing methods on the base-to-novel generalization setting. Right: We evaluate our approach on four diverse image recognition benchmarks for CLIP and show consistent gains over previous state-of-the-art approaches.